Spatial Analysis: Housing Price Prediction
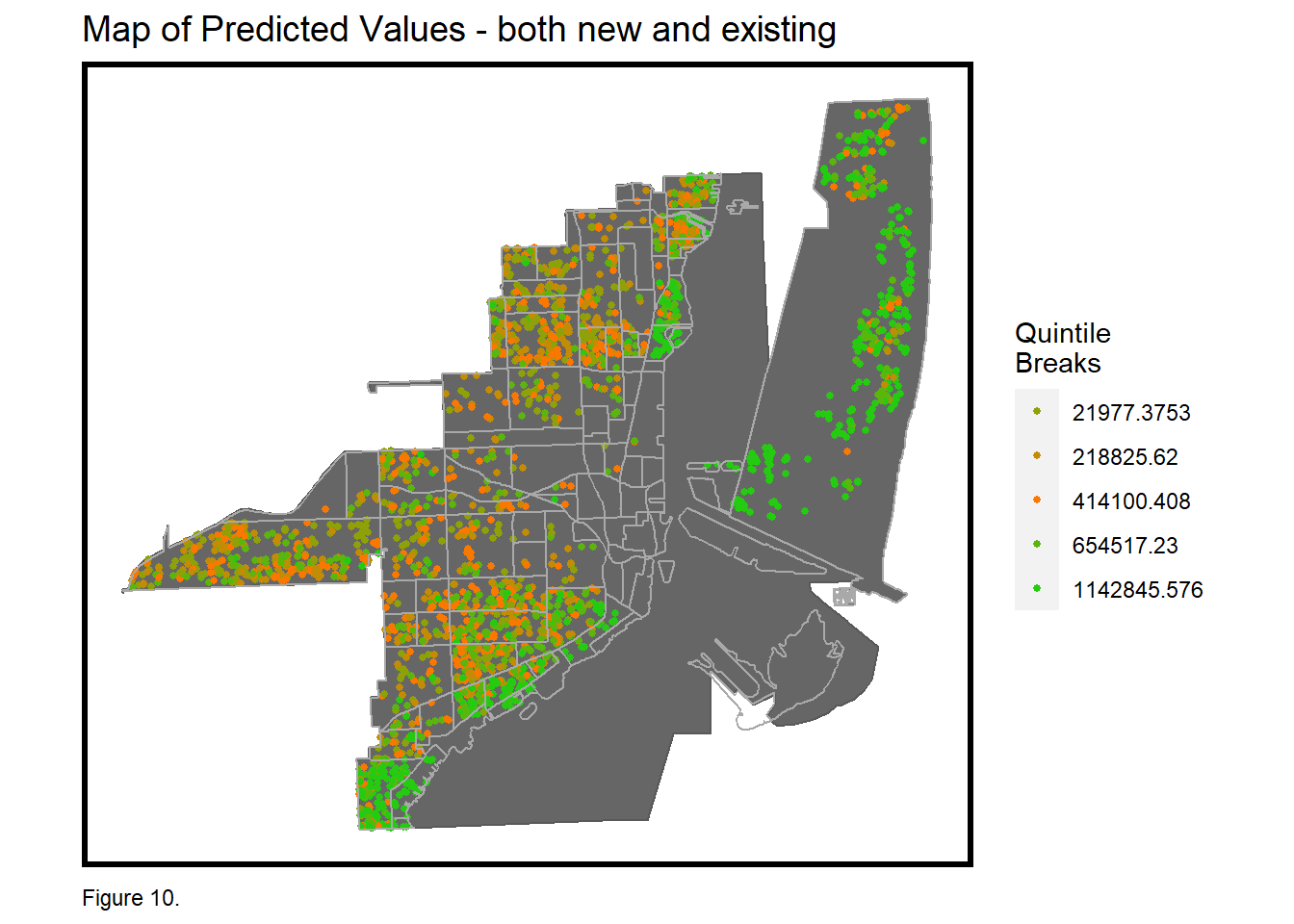
Zillow’s housing price prediction tool helps its users see the estimated value of their home with ease, based on algorithms using available determinants of sale prices such as the number of beds, number of bathrooms, and square footage. With the availability of huge volume of data, such algorithms aim to provide stakeholders such as house buyers, real estate agents, and developers with useful information to aid their decision-making process. While its predictions are helpful, Zillow always strive to improve and update their predictive models for higher accuracy and generalizability. Inaccurate predictions will impact the reputation of the company and financial consequences. Hence, our team has developed a predictive model that factors in available local intelligence in hopes of delivering a better model for home prices prediction.
After brainstorming and researching the factors that influence home prices, our team gathered publicly-available data on the homes in Miami and Miami Beach which are two cities in Florida. For simplicity, we refer them collectively as Miami. We used linear (OLS) regression as the basis for our model, factoring in variables of internal characteristics of the house, local amenities, and spatial structure of the location. Our modeling strategy is to include the variables that explain the most for the prediction and represent local intelligence. However developing an all-round omnibus statistical model that take into consideration of all these aspects while balancing the criteria of accuracy and generalizability proved to be a challenging task, in part because of the overfitting of variables. Therefore, as our results suggest, we would not recommend it as-is to Zillow since there are high variances and distortions of the true value sale price due to overfitting or misspecification of variables including local amenities, zoning and neighborhoods, which led to sale price predictions that generalize well with high-income neighborhoods but not others (which have high errors or inaccuracy). For these reasons, even if the adjusted R-square were very high (in our case 88.4% for the trained model), it will not be helpful when predicting new unseen data. Alternative solutions to re-specify and improve this model has been proposed and discussed in detail.
disclamer: this project is a part of a graduate course